

2025年1月15日、SHIFTが手がける技術イベント「SHIFT EVOLVE」にて、「インシデント対応の最適解ってなんだろう(AWSぶっちゃけ討論会 vol.2)」と題されたセッションを開催しました。
2024 Japan AWS All Certifications Engineerに選出され、SHIFTのCCoE(Cloud Center of Excellence)リーダーとしてAWS事業を牽引する大瀧 広宣が、さまざまな業界のエキスパートを招き、教科書に載っていない、検索しても出てこない、AWSセキュリティの現実を掘り下げる「AWSぶっちゃけ討論会」シリーズ。
2回目となる今回は、インシデントが起こったときの対応法や体験談、障害訓練の具体的な方法、おすすめの監視方法についてディスカッションしました。
※「AWSぶっちゃけ討論会」シリーズ初回の様子は以下。
関連コンテンツ

※SHIFT EVOLVEとは?
SHIFTグループが主催する技術イベント。 エンジニアコミュニティから技術をEVOLVEしていこう、という想いで運営し、メンバー登録者数は3,700人を超える(2025年2月時点)。開催予定のイベントは以下よりチェック。
https://shiftevolve.connpass.com/
-

草間 一人 PagerDuty株式会社 Product Evangelist
PagerDutyのProduct Evangelistとして、インシデント管理ソリューションに関する情報発信やコミュニティづくりに携わる。過去には通信事業者でプラットフォームエンジニアを務めたのを皮切りに、いくつかの外資系企業でプロフェッショナルサービスやプリセールスエンジニアとしてクラウドネイティブやプラットフォーム製品に携わるなど、10年以上さまざまな形でプラットフォームに関与している。2023年11月より現職。一般社団法人クラウドネイティブイノベーターズ協会 代表理事。Platform Engineering Meetupオーガナイザー。
-

土佐 鉄平 フリー株式会社 執行役員CIO
新卒で現・三菱UFJ銀行のシステム子会社に入社。前半8年間は営業店事務支援系サービスを中心に担当し、銀行合併プロジェクトなども経験。後半5年間は研究開発部門に所属し、ビッグデータ技術などの新技術を銀行向けに導入推進。2015年10月にfreeeに転職。当初2年間は会計プロダクトエンジニアを担当しつつCSIRTを兼務。その後CSIRTの一人目の専任担当としてアサインされ、そのままCISO 兼 CIOとして社内IT全般の責任者として勤務。2022年からはCIOに専任。
-

大瀧 広宣 株式会社SHIFT ソリューション事業部セキュリティサービス部 AWSセキュリティコンサルタント
2015年に某中古車検索サイト運営会社のオンプレからAWSへのデータセンター延伸をきっかけに社内CCoEリーダーとしてAWS事業を牽引。3年前に某中堅リユース企業のAWSセキュリティ推進のPMをきっかけに個人情報保護、DLP対策、SOC、CSPM、SAST導入を専門分野として活動。2024 Japan AWS All Certifications Engineers へ選出、現在はSHIFT社内のCCoEリーダーとしてAWS事業を牽引。



目次
LT「AWSマルチアカウント統制環境のすゝめ」
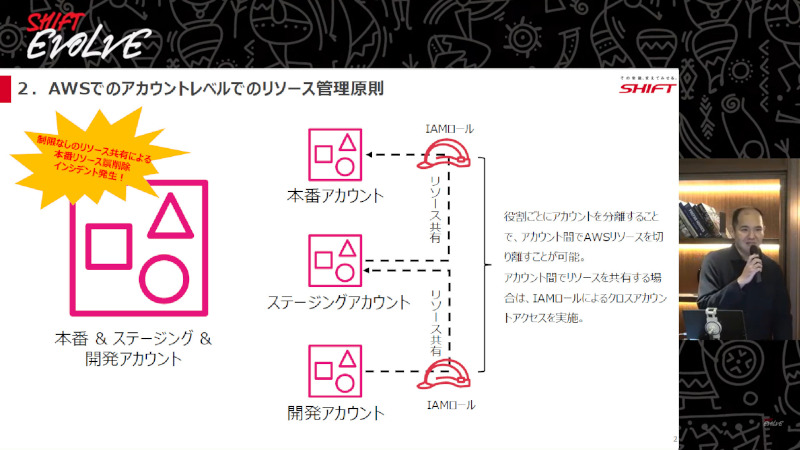
パネルディスカッションの前に、SHIFTのナショナルセキュリティ事業部でシニアコンサルタントとして、官公庁案件におけるガバメントクラウド移行支援などを担当している松尾が、「AWSマルチアカウント統制環境のすゝめ」というタイトルでLTを行いました。
「AWS上のリソース管理をシングルアカウントで行うとき、例えば本番、ステージング、開発の全環境を1つのアカウントでまとめて統制・管理できますが、本番のリソースを誤って削除するなどのリスクがつきものです。
ですから基本的には、本番、ステージング、開発のそれぞれでアカウントをわけて、アカウント間でリソースを分離します。アカウント間でリソース共有が必要な場合は、IAMのスイッチロールでのクロスアカウントアクセスで必要最小限のアクセスにより実施します」
その際に、AWSマルチアカウント統制環境を構築・管理するマネージドサービス「AWS Control Tower」が有用だと、松尾は説明します。
一般的にリソース操作に対して、シングルアカウントは統制がかかりにくいものの自由度が高い反面、マルチアカウントは統制がかかるものの自由度は下がります。
そこで、例えば複数のAWSアカウントの一元管理ができる「AWS Organizations」にてコントロール(旧ガードレール)を適用しない組織単位(OU)を作成し、ここに本来シングルアカウントで管理したいAWSアカウントを登録します。
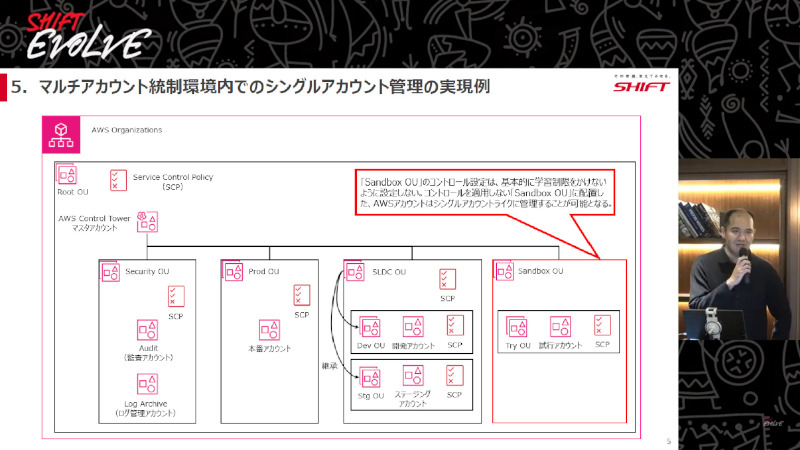
「これによって、ほかのOUによるガードレール設定を継承せず、個々のシングルアカウント内でService Control Policy(SCP)、Config Rulesなどの設定を完結できます。つまり、AWSのマルチアカウント統制環境内で、シングルアカウントライクに管理できるようになります」
詳細は以下の記事をご覧ください。
AWSマルチアカウント統制環境の構築(AWS Control Tower シリーズ vol.1)
また、SHIFTのAWS CCoEチームの取り組みについては、SHIFT Group技術ブログ「AWS CCoE Blog」もあわせてご覧ください。
SHIFT Group技術ブログ「AWS CCoE Blog」
パネルディスカッション「インシデント対応の最適解ってなんだろう」
ここからは、登壇者3名によるパネルディスカッションの様子を、特に印象的なポイントをピックアップする形でお伝えします。
テーマ:障害訓練の具体的な取り組み方
土佐:障害訓練は2019年から毎年10月にやっています。きっかけは2018年10月末に発生した大障害で、2時間半ぐらい全サービスを止めてしまう事象が発生しました。
その反省をもとに、さまざまなリスク管理や障害発生時の初動対応を整備していったのですが、そのなかで「障害訓練もやらなくては」と。
「障害訓練月間」とした10月には、毎年大小さまざまな規模の訓練を行い、社内でムーブメントをつくっていきました。
大瀧:具体的にはどのような障害訓練を行っているんですか?
土佐:リアリティをもってやろうということで、訓練専用の環境を用意して攻撃を受けたログを仕込み、障害対応するメンバーが攻撃を検知できるか試しています。
訓練内容も、対応するメンバーも伏せています。運営メンバーは毎年違いますが、2024年にはCISOとCIOを中心に、セキュリティのメンバー数人と広報が訓練を設計しました。
実践してみると想定どおり進まない場面もあり、気づきが多いですね。
草間:きちんと実践できていることが本当にすごいですよね。もちろん、本には具体的な訓練方法は書いてあるのですが、実行できるかは別問題です。障害訓練をトップの方が大切なことだと認識しているからこそだなと。
テーマ:大規模インシデント発生時のメディア対応
大瀧:大規模インシデントが発生した時のメディア対応については、いかがですか?
草間:インシデント発生時は、シングルソース・オブ・トゥルース(SSOT)が大切です。つまり、情報を集約・コントロールすること。
情報を集約・意思決定するためのウォールームを物理的に設置する、ZoomやTeamsなどで窓を立ち上げるなどの対応策が考えられます。
そこでは、インシデントコマンダー(インシデントの解決に必要な意思決定を行う責任をもつ人)や、あるいはインシデントコマンダーから委任された広報官などが、統一された情報を発表します。
土佐:当社でも、障害対応を優先的に話し合う会議室を設けています。また、障害発生時の報告用テンプレートをつくったり、フローを整備したりしています。
ちなみに、メディア対応に関しては広報が専任で担当しています。障害訓練にも、基本的には広報を巻き込んでいますね。
テーマ:インシデントコマンダーの決め方
草間:もともとインシデントコマンダーは、アメリカの消防現場から生まれた概念です。そのため、基本的には、障害に最初に対応する人が第一のインシデントコマンダーになります。
ただ、より被害が広範になったり高度になったりすると、より上位の人にインシデントコマンドが委譲されます。
土佐: インシデントコマンダーは、紆余曲折を経てかなり成熟した状態で運用できていて、基本的にはエンジニアチームのメンバーからタスクフォース的に集まる「委員会制」です。
月曜日から金曜日まで当番を決めていて、その当番の人が初動をとにかくやると。障害速報が上がったら、事前に決めた当番が現場にいちはやく駆けつけて対応します。
委員会の人たちは一定の経験を積んでいるので、初動対応や情報整理、障害のレベル判定もできます。
加えて、委員会ではメンバーを半年に1回の頻度で入れ替える「任期制」を採用しています。ただし、リーダーは変えません。
リーダーの役割はそれほど多くはなく、当番にもなりません。障害対応の経験はエンジニアがキャリアを積むうえでプラスに働きますし、ほかのプロダクトのことを知る機会にもなりますよね。
草間:任期制、すごくいいですね。自分がエンジニアとして一番成長したのは、やっぱり障害対応しているときなんですよね。
全力で頭を使うし、すべての知識と経験を総動員して対応していくので、エンジニアとしてワンランクアップしたという感覚がすごくあるんですよ。
インシデントコマンダーに向いている人の特徴をよく聞かれるんですが、何か特定の技術のプロフェッショナルである必要はないんですね。
それよりも、インシデントが発生したときに権威をもって対応できる人だとか、システム間の関連あるいは組織間の関連がわかっていて、適切な人にアプローチできる人が向いているといわれます。
任期制だと、多数の人が経験を積めますよね。
土佐:実は最初は任期制ではなかったのですが、経験豊富な人がつねに対応している現状を改善するためにはじめました。
テーマ:おすすめの監視方法、AIによる検知・対応
土佐:当社はDatadogを主に使っていて、リソース監視のアラートやログ監視からのアラートを見ていますね。ログに関しては、CSIRTやPSIRTが整備を進めてくれています。
あとは、ログをできる限り一箇所に集めてAWS SIEMなどを使って横断的に見られるように、日々PSIFTチームが努力してくれていますね。
大瀧:freeeさんの技術ブログを拝見していると、トリアージの整備やレッドチームの配置など、多様な取り組みがありますよね。
土佐:トリアージでは障害レベルを定義していて、レベルに応じて巻き込みの範囲や振り返りの方法などが決められています。工数を削減するためです。
また、PSIRTのなかにレッドチームとブルーチームを設けて役割分担をしています。例えば、以前外注していた脆弱性診断などはレッドチームで対応しています。
大瀧:全社的なアセスメントなども社内で対応しているのですか?
土佐:そのとおりです。業界標準的な指標で見たときの脆弱性をプロダクト別に色分けし、対応しているポイントは経営陣に対して4半期に1回の頻度で報告しています。
大瀧:ちなみに、最近話題のAIについて、インシデントの兆候を掴むために活用していますか?
草間:AIと一言でいっても、生成AIや機械学習などがありますよね。例えば、アノマリーディテクションは大量のデータを機械学習させておいて、何か異常があったときにアラートを上げさせるなどの形で広く使われています。
また、生成AIも多様な使い方があると思っていて、例えばコミュニケーションツールのやりとりを生成AIがつねに学習していれば、インシデント対応時の状況をチャットベースで確認できますよね。
そうすれば、現場対応している人が都度工数を割いて状況報告をしなくても済みます。
特に、今年はAIエージェントが高度化するといわれています。問題を切り分け、かつ必要なところに連絡するAIエージェントが出てくるのではないでしょうか。
大瀧:インシデント対応へのAI活用の動向を、今後も探っていきたいですね。
パネルディスカッションのほかのパートや全編をご覧になりたい方はこちら
―――さまざまなテーマでイベントを開催中のSHIFT EVOLVE。次回以降もぜひお楽しみに。
※本記事の内容および取材対象者の所属は、イベント開催当時のものです





